- 定义:Spark是一个用来实现快速而通用的集群计算的平台。一个大一统的软件栈。
- 组件:

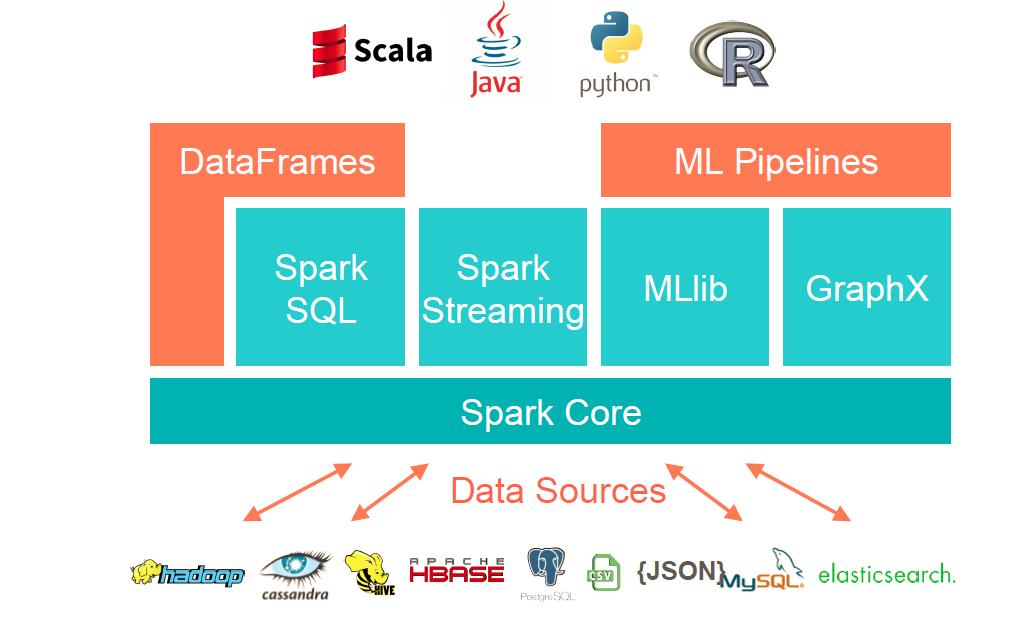
- Spark CoreSpark Core实现了Spark的基本功能,包含任务调度,内存管理,错误恢复,与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(RDD)的API定义。RDD表示分布在多个计算节点上可以并运行操作的元素集合,是Spark主要的编程抽象。 Spark Core提供了创建和操作这些集合的多个API
- Spark SQLSpark SQL是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。Spark SQL支持多种数据源,比如Hive表,Parquet以及JSON等。除了Spark提供了一个SQL接口,Spark SQL还支持开发者将SQL和传统的RDD编程的数据操作方式相结合,不论是使用Python,Java和Scala,开发者都可以在单个的应用中使用 SQL和复杂的数据分析。通过与Spark所提供的丰富的计算环境进行如此紧密的结合,Spark SQL得以从其他开源数据仓库工具中脱颖而出。
- Spark StreamingSpark Streaming是Spark提供的对实时数据进行流式计算的组件。比如生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队 列,都是数据流。Spark Streaming提供了用来操作数据流的API,并且与Spark Core中的RDD API高度对应。这样一来,程序员编写应用时的学习门槛就得以降低,不论是操作内存或是硬盘中的数据,还是操作实时数据流,程序员都能应对自如。从底层设 计来看,Spark Streaming支持与Spark Core同级别的容错性,吞吐量以及可伸缩性。
- MLlibSpark中还包含了一个提供常见的机器学习(ML)功能的程序库,叫做MLlib。MLlib提供了很多种机器学习算法,包括分类,回归,聚类, 协同过滤等,还提供了模型评估,数据导入等额外的支持功能。MLlib还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化算法。所有这些方法 都被设计为可以在集群上轻松伸缩的构架。
- GraphxGraphx是用来操作图的程序库,可以进行并行的图计算。与Spark Streaming和Spark SQL类型,Graphx也扩展了Spark的RDD API,能用来创建一个顶点和边都包含任意属性的有向图。Graphx还支持针对图的各种操作(比如进行图分割的subgraph和操作所有顶点的 mapVerrices),以及一些常用图算法(比如PageRank和三角计数)。
- 集群管理器就底层而言,Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在 各种集群管理器上运行,包括Hadoop YARN,Apache Mesos,以及Spark自带的一个简易调度器,叫做独立调度器。
- 下载安装Spark
- http://spark.apache.org/downloads.html下载spark-version-bin-hadoopbversion.tgz
- 解压
tar -xf spark-version-bin-hadoopversion.tgz - 执行Spark Shell
./bin/pyspark //Python shell ./bin/spark-shell //Scala shell
分类: Hadoop生态
9 条评论
hh55betcc · 2025-12-19 20:11
Heard about hh55betcc, decided to give it a go. Not gonna lie, pretty impressed. The odds are decent and the layout’s easy to navigate. Worth a punt if you ask me! Check it out! hh55betcc
zalv777 · 2025-12-24 10:53
Alright folks, zalv777 is where the party’s at! Seriously, give it a whirl. You might just get lucky. Check it out here: zalv777
phtaya11 · 2026-01-12 11:56
https://www.phtaya11y.com I am thanksful for this post!
tg77com · 2026-01-14 18:25
tg77com https://www.tg77com.org
ph789 login · 2026-01-14 22:18
ph789 login https://www.ph789-login.com
bk8casino · 2026-01-15 03:27
bk8casino https://www.bk8casinovs.com
phrushcblub · 2026-03-14 17:28
Yo – been vibin’ with phrushcblub lately. Solid selection and something for most players. Def worth checking out when you get a chance phrushcblub.
pkr777login · 2026-03-14 17:29
PKR777Login is where I get logged in! Easy peasy! No hassle. Get in the game at pkr777login. Tara!
pkslots · 2026-03-14 17:29
PK Slots? Game face on! Been hearing some good things lately. Check out PKSlots at pkslots and may the odds be ever in your favor!